Apache Spark
Overview
Apache Spark is an open-source analytics engine & cluster-compute framework that processes large-scale data.
Spark supports in-memory caching and optimized query execution for fast analytics. It has built-in modules for machine learning, graph processing, streaming, and SQL
Github: https://github.com/gitorko/project08
Apache Spark
Spark applications run as independent sets of processes on a cluster. Spark uses RDD (Resilient Distributed Datasets) to store shared data.
| Apache Spark | Apache Kafka |
|---|---|
| Analyze large datasets that cant fit on single machine (big data) | Process large events as they happen and stores them distributed manner |
| Processing data task runs on many nodes | Processing data task is delegated to clients/consumers |
| Provides machine learning libraries (MLlib), graph processing and SQL querying | No machine learning libraries/ Graph processing / SQL querying provided |
| Batch and stream processing, ETL jobs, and complex analytics | Real-time data streaming, building data pipelines, and handling event-driven architectures |
| Not suited for event or message handling (producer-consumer) | Integrating disparate systems for message passing and event storage (producer-consumer) |
| Spark can be complex to set up and tune, especially in a distributed environment | Kafka is relatively easier to set up for streaming and messaging |
Code
1package com.demo.project08.service;
2
3import java.util.ArrayList;
4import java.util.Arrays;
5import java.util.List;
6
7import lombok.extern.slf4j.Slf4j;
8import org.apache.spark.api.java.JavaPairRDD;
9import org.apache.spark.api.java.JavaRDD;
10import org.apache.spark.api.java.JavaSparkContext;
11import org.apache.spark.sql.Dataset;
12import org.apache.spark.sql.Row;
13import org.apache.spark.sql.SparkSession;
14import scala.Tuple2;
15
16@Slf4j
17public class SparkService {
18
19 private static SparkSession sparkSession;
20 private static JavaSparkContext sparkContext;
21
22 private String sparkMaster;
23
24 public SparkService(String sparkMaster) {
25 this.sparkMaster = sparkMaster;
26 }
27
28 // Singleton for SparkSession
29 private SparkSession getSparkSession() {
30 if (sparkSession == null) {
31 synchronized (SparkService.class) {
32 if (sparkSession == null) {
33 sparkSession = SparkSession.builder()
34 .appName("Spark App")
35 .master(sparkMaster)
36 .getOrCreate();
37 }
38 }
39 }
40 return sparkSession;
41 }
42
43 // Singleton for SparkContext
44 private JavaSparkContext getSparkContext() {
45 if (sparkContext == null) {
46 synchronized (SparkService.class) {
47 if (sparkContext == null) {
48 var sparkSession = getSparkSession();
49 sparkContext = new JavaSparkContext(sparkSession.sparkContext());
50 }
51 }
52 }
53 return sparkContext;
54 }
55
56 public List<String> getWordCount() {
57 JavaRDD<String> inputFile = getSparkContext().textFile("/tmp/data/word-file.txt");
58 JavaRDD<String> wordsFromFile
59 = inputFile.flatMap(s -> Arrays.asList(s.split(" ")).iterator());
60 JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
61 List<Tuple2<String, Integer>> output = countData.collect();
62 List<String> result = new ArrayList<>();
63 for (Tuple2<?, ?> tuple : output) {
64 log.info(tuple._1() + ": " + tuple._2());
65 result.add(tuple._1() + ": " + tuple._2());
66 }
67 return result;
68 }
69
70 public List<String> processJson() {
71 // Create a sample dataset
72 Dataset<Row> data = getSparkSession().read().json("/tmp/data/customers.json");
73
74 // Perform a transformation
75 Dataset<Row> result = data.select("name").where("age > 30");
76
77 // Collect the result into a list
78 var names = result.toJavaRDD()
79 .map(row -> row.getString(0))
80 .collect();
81
82 names.forEach(n -> {
83 log.info("Name: {}", n);
84 });
85 return names;
86 }
87
88 public void shutdownSpark() {
89 if (sparkContext != null) {
90 sparkContext.stop();
91 sparkContext = null;
92 }
93 if (sparkSession != null) {
94 sparkSession.stop();
95 sparkSession = null;
96 }
97 }
98
99}
Setup
1# project08
2
3Apache Spark
4
5### Version
6
7Check version
8
9```bash
10$java --version
11openjdk 17
12```
13
14### Dev
15
16To build the code.
17
18```bash
19./gradlew clean build
20./gradlew shadowJar
21cp build/libs/project08-fat-1.0.0-all.jar /tmp/data/
22cp src/main/resources/word-file.txt /tmp/data
23cp src/main/resources/customers.json /tmp/data
24```
25
26```bash
27cd docker
28docker-compose up -d
29docker-compose down
30ipconfig getifaddr en0
31```
32
33Scala version check on spark cluster
34
35```bash
36spark-shell
37scala.util.Properties.versionString
38res0: String = version 2.12.18
39```
40
41```bash
42cd /opt/bitnami/spark
43cd bin
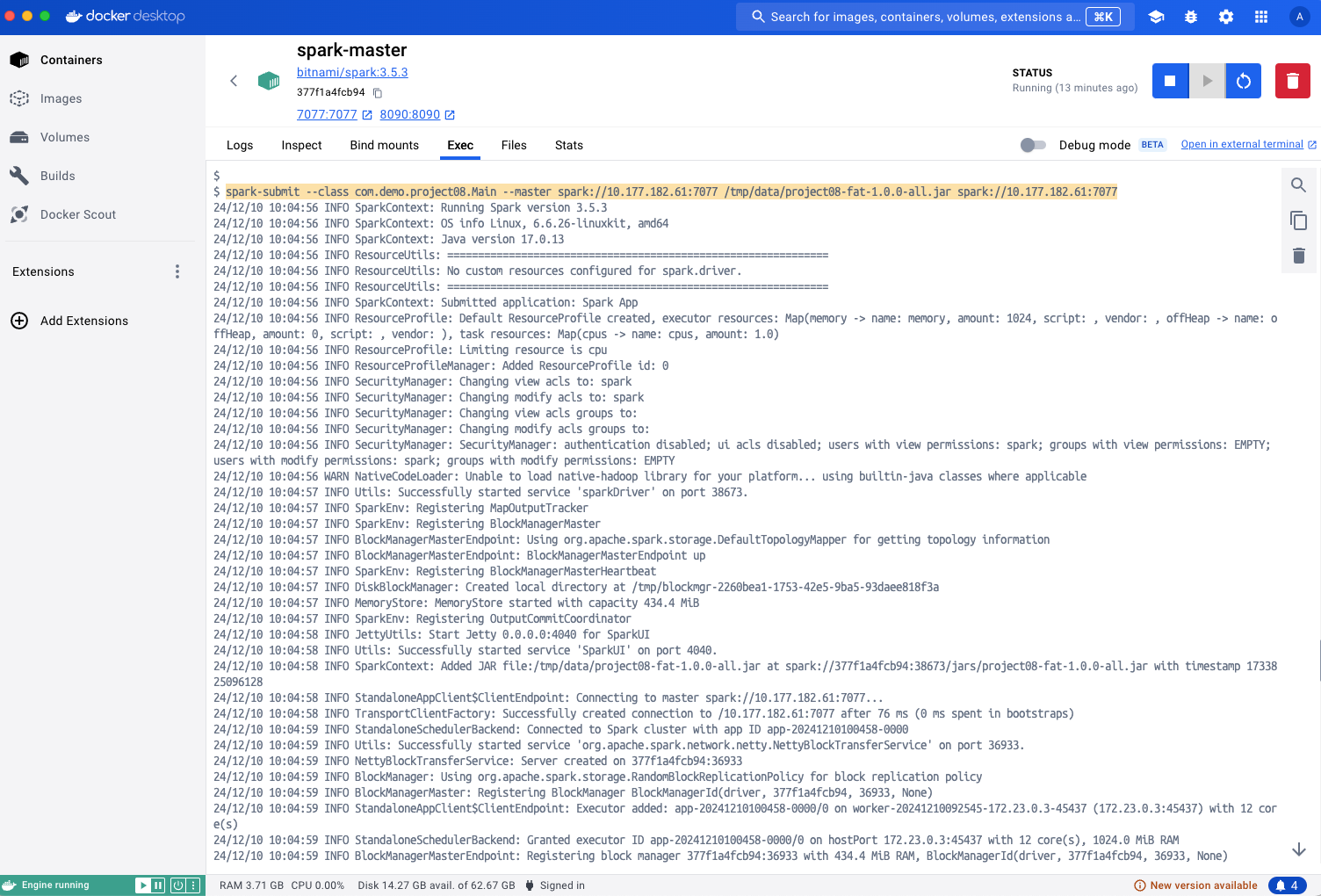
44spark-submit --class com.demo.project08.Main --master spark://10.177.182.61:7077 /tmp/data/project08-fat-1.0.0-all.jar
45```
46
47
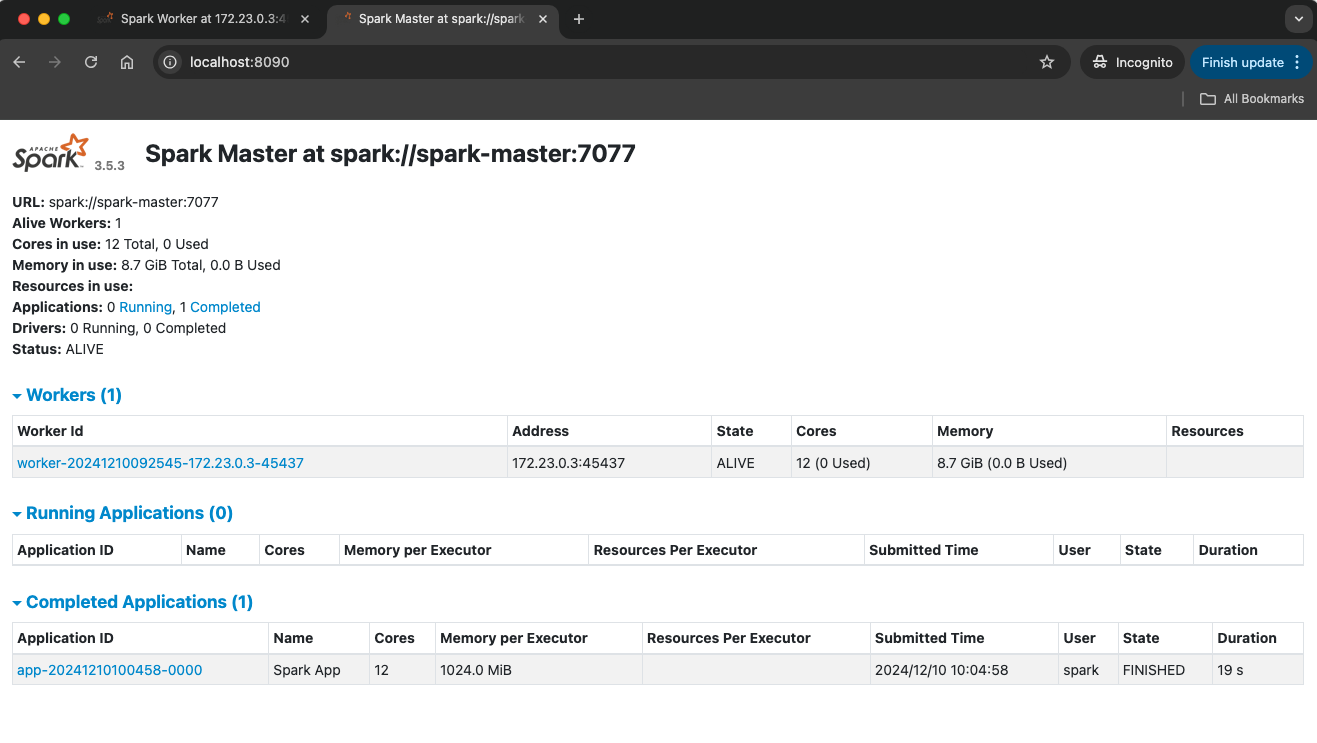
48http://localhost:8090
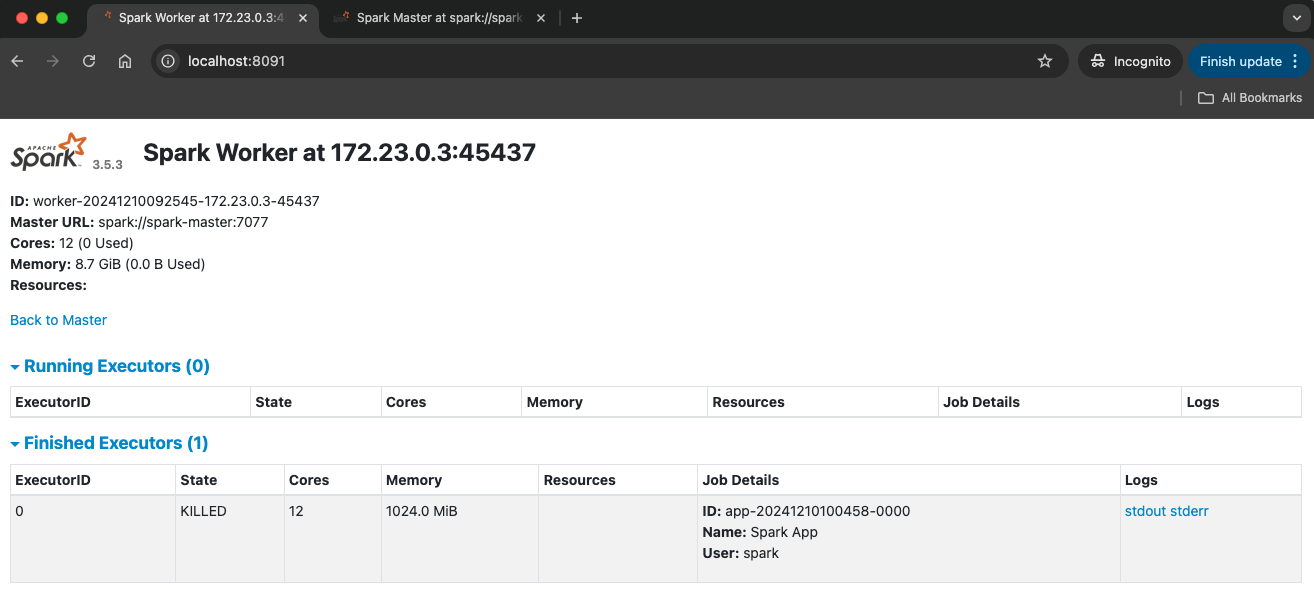
49http://localhost:8091References
comments powered by Disqus