Grokking the Coding Interview
Overview
A comprehensive guide for java coding interviews covering areas like algorithms, datastructures, sorting, leetcode problems, concurrency, java fundamentals.
Github: https://github.com/gitorko/project01
Preparation
- We will first understand the fundamentals of data structure, like how heap, queue, stacks work and how to implement them from scratch.
- Then we will look at the various sorting algorithms.
- Then we will move to leetcode problems covering easy, medium & hard problems.
- Then we will move to concurrency problems, how atomic variable work, how locks work etc.
- Then we will cover some SQL and database queries.
- The problems solved here are concise & small making it easy to understand and revise.
- All problems solved here are developed with test driven approach, with various test that can be run locally.
- Each of the solutions follow certain pattern. Eg: if you learn back-tracking solution in one problem the pattern is similar when you solve it in other problem. This is very important when it comes to the learning aspect.
- Most problems have a parent problem, Once you solve this parent problem you can solve various subset or variation of this problem. Such problems are grouped as similar in the solutions.
Approach To Solve
Given a problem here are some questions that should help you figure out the general direction of how to solve it
- Which data structure can I use? Arrays, LinkedList, HashMap, Heap, Tree, or Trie
- Do I need to use 2 data structures? eg: LRU
- How do I break the problem into smaller units, is there a problem within a problem, can i write a decision tree?
- Does this problem look similar to other problems you have solved?
- Will sorting make the problem easier to solve?
- Can I use any algorithmic techniques, like bfs, dfs, two pointer etc.
- Do any design patterns apply that could make it easier to maintain, like observer pattern?
- What is the time & space complexity? Best case, worst case time complexity? Average case is usually difficult to derive.
Tips
- Linked list problems often use a dummy node.
- To delete a node in the link list you need previous node or be position one node behind.
- Time complexity is O(number of branches ^ n)
- In-order traversal of BST results in ascending order array.
- BFS requires a queue, DFS requires recursion.
- If the char set is bound to 26 chars, use char[26] array instead of Map or Set.
Algo Techniques
- Sorting
- Map & Set
- Recursion
- Fast pointer & Slow pointer
- Min-Heap vs Max-Heap (Priority Queue)
- Binary search
- BFS vs DFS
- Two Pointers
- Sliding Window
- Fast pointer vs Slow pointer
- Backtracking
- Matrix
- Prefix sum
- Divide & Conquer
- Memoization / Dynamic programming
- Greedy
- Topological Sort
- Intervals
- Cyclic Sort
- Bitwise XOR / Bit manipulation
- Trie
- Stacks & Queue
Big-O
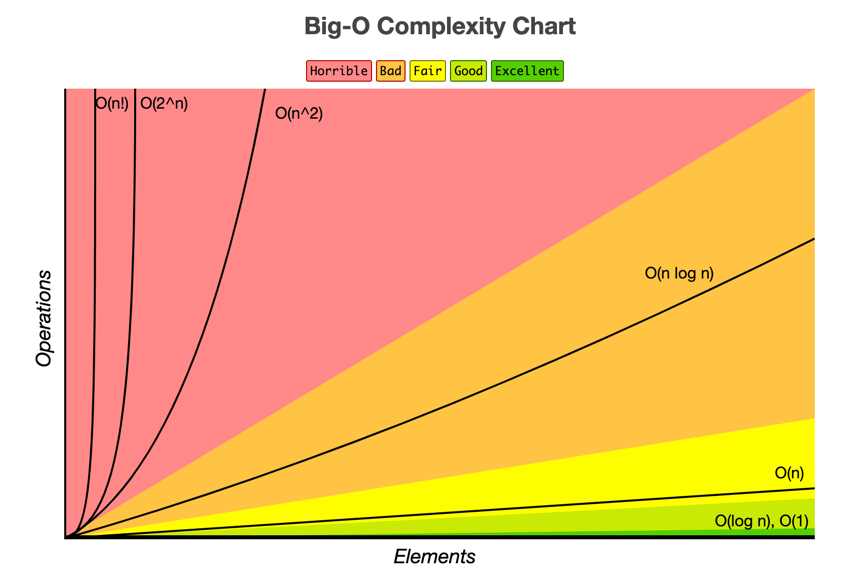
1log(n) < √(n) < n < nlog(n) < n^2 < n^3 < 2^n < n!
Algorithms and Data Structures Cheatsheet
Coding
Sorting
| Id | Leetcode | Solution | Type |
|---|---|---|---|
| 1 | Bubble Sort | Solution | EASY |
| 2 | Selection sort | Solution | EASY |
| 3 | Insertion sort | Solution | EASY |
| 4 | MergeSort | Solution | MEDIUM |
| 5 | 912. Sort an Array | Solution | MEDIUM |
| 6 | QuickSort | Solution | MEDIUM |
| 7 | 912. Sort an Array | Solution | MEDIUM |
| 8 | Shell sort | Solution | HARD |
| 9 | Counting sort | Solution | EASY |
| 10 | Radix sort | Solution | MEDIUM |
| 11 | Bucket sort | Solution | EASY |
| 12 | Heap sort | Solution | MEDIUM |
| 13 | 704. Binary Search | Solution | EASY |
| 14 | Employee Search | Solution | EASY |
Data Structure
| Id | Leetcode | Solution | Type |
|---|---|---|---|
| 1 | Implement Circular Array | Solution | EASY |
| 2 | 622. Design Circular Queue | Solution | MEDIUM |
| 3 | Implement ArrayList with array | Solution | EASY |
| 4 | Insert to BST, Delete from BST, Find from BST | Solution | EASY |
| 5 | Implement Doubly Linked List | Solution | EASY |
| 6 | 707. Design Linked List | Solution | MEDIUM |
| 7 | 706. Design HashMap | Solution | EASY |
| 8 | Implement Map | Solution | MEDIUM |
| 9 | Implement Max Heap | Solution | EASY |
| 10 | Implement Min Heap | Solution | EASY |
| 11 | Implement Queue | Solution | EASY |
| 12 | Implement Stack | Solution | EASY |
| 13 | 208. Implement Trie, Prefix Tree | Solution | EASY |
| 14 | 225. Implement Stack using Queues | Solution | EASY |
LeetCode - Easy
LeetCode - Medium
LeetCode - Hard
Concurrency
| Id | Leetcode | Solution | Type |
|---|---|---|---|
| 1 | Long Adder & Long Accumulator | Solution | MEDIUM |
| 2 | Callable | Solution | EASY |
| 3 | Create Dead Lock | Solution | MEDIUM |
| 4 | Produce Consumer | Solution | EASY |
| 5 | Produce Consumer | Solution | EASY |
| 6 | Produce Consumer | Solution | EASY |
| 7 | Semaphore | Solution | MEDIUM |
| 8 | ScheduledExecutorService | Solution | MEDIUM |
| 9 | Stop Thread | Solution | EASY |
| 10 | Stop Thread | Solution | EASY |
| 11 | Print Even Odd | Solution | EASY |
| 12 | Thread Starvation | Solution | EASY |
| 13 | Thread Abort Policy | Solution | EASY |
| 14 | Read Write lock | Solution | MEDIUM |
| 15 | ReentrantLock | Solution | MEDIUM |
| 16 | Stamped Lock | Solution | MEDIUM |
| 17 | Fork Join | Solution | MEDIUM |
| 18 | Common Words | Solution | EASY |
| 19 | Common Words multi thread | Solution | MEDIUM |
| 20 | Concurrent Modification | Solution | EASY |
| 21 | Cyclic Barrier | Solution | MEDIUM |
| 22 | Count Down Latch | Solution | EASY |
| 23 | Increment Array | Solution | MEDIUM |
| 24 | Phaser | Solution | MEDIUM |
| 25 | Completable Future | Solution | EASY |
| 26 | AtomicStampedReference | Solution | MEDIUM |
| 27 | AtomicReference | Solution | MEDIUM |
| 28 | Implement Custom Thread Pool | Solution | MEDIUM |
| 29 | Implement Custom Semaphore | Solution | MEDIUM |
| 30 | Parallel Stream | Solution | MEDIUM |
Java Concurrency
LinkedBlockingQueue (unbounded)
- SynchronousQueue - space for only 1
- ArrayBlockingQueue (bounded)
- DelayQueue - unbounded blocking queue of delayed elements, element can only be taken when its delay has expired.
Thread Pool Size
- cpu intensive = num of cores
- io intensive = time it takes for IO to complete.
- ideal thread pool size = cores * (1 + (wait time/cpu time))
Types of ExecutorService
- ExecutorService uses BlockingQueue by default
- newFixedThreadPool - LinkedBlockingQueue
- newSingleThreadExecutor
- newCachedThreadPool - SynchronousQueue, dynamically scale the threads to handle the amount of tasks, threads are idle for 60 second, they will be scaled down
Rejection policy
- AbortPolicy - This is the default policy. It causes the executor to throw a RejectedExecutionException.
- CallerRunsPolicy - the producer thread will be employed to run the task it just submitted. This is effective back pressure.
- DiscardOldestPolicy - accept the task and throw away the oldest task in the BlockingQueue
- DiscardPolicy - accept the task but silently throw it away
- Custom Policy - We can implement the RejectedExecutionHandler interface and provide our own logic to handle
Mutex vs Semaphore
- Mutex (or Mutual Exclusion Semaphores) is a locking mechanism used to synchronize access to a resource. Only one task can acquire the mutex. It means there will be ownership associated with mutex, and only the owner can release the lock (mutex).
- Semaphore (or Binary Semaphore) is signaling mechanism (“I am done, you can carry on” kind of signal). A binary semaphore is NOT protecting a resource from access. Semaphores are more suitable for some synchronization problems like producer-consumer.
Short version:
- Mutex can be released only by the thread that had acquired it.
- Binary Semaphore can be signaled by any thread (or process).
Read vs Write lock
Read Lock – if no thread acquired the write lock or requested for it then multiple threads can acquire the read lock Write Lock – if no threads are reading or writing then only one thread can acquire the write lock
Concurrency
- CyclicBarrier - CyclicBarriers are used in programs in which we have a fixed number of threads that must wait for each other to reach a common point before continuing execution.
- Phaser
- CountDownLatch
- Exchanger - share objects between two threads of type T
- Semaphore
- SynchronousQueue
More Questions
- ShutdownNow vs Shutdown
- Dynamic Striping - Striped64 class
- Deadlock vs Livelock
- Lock vs Synchronized Block
- ReentrantReadWriteLock.ReadLock vs ReentrantReadWriteLock.WriteLock
- Stamped lock - optimistic locking
- DelayQueue
SQL
Start a Postgres DB
1docker run -p 5432:5432 --name pg-container -e POSTGRES_PASSWORD=password -d postgres:9.6.10
2docker ps
3docker exec -it pg-container psql -U postgres -W postgres
4CREATE USER test WITH PASSWORD 'test@123';
5CREATE DATABASE "test-db" WITH OWNER "test" ENCODING UTF8 TEMPLATE template0;
6grant all PRIVILEGES ON DATABASE "test-db" to test;
7\c test-db
8
9docker stop pg-container
10docker start pg-container
Create the tables & Seed the test data
1create table department
2(
3 id serial not null
4 constraint department_pk
5 primary key,
6 name varchar
7);
8
9alter table department owner to test;
10
11create table employee
12(
13 id serial not null
14 constraint employee_pk
15 primary key,
16 name varchar,
17 salary integer,
18 department_id integer,
19 manager integer,
20 dob date
21);
22
23alter table employee owner to test;
24
25create table project
26(
27 id serial not null
28 constraint project_pk
29 primary key,
30 name varchar
31);
32
33alter table project owner to test;
34
35create table employee_project_mapping
36(
37 id serial not null
38 constraint employee_project_mapping_pk
39 primary key,
40 emp_id integer
41 constraint fk1
42 references employee
43 on update cascade on delete cascade,
44 project_id integer
45 constraint fk2
46 references project
47 on update cascade on delete cascade
48);
49
50alter table employee_project_mapping owner to test;
51
52INSERT INTO department (id, name) VALUES (1, 'IT');
53INSERT INTO department (id, name) VALUES (2, 'Sales');
54INSERT INTO department (id, name) VALUES (3, 'Admin');
55
56INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (1, 'Joe', 85000, 1, 5, '1990-02-10');
57INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (2, 'Henry', 80000, 2, null, '1975-02-10');
58INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (3, 'Sam', 60000, 2, 4, '1975-02-10');
59INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (4, 'Max', 90000, 1, 5, '1981-02-10');
60INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (5, 'Janet', 69000, 1, 1, '1983-02-10');
61INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (6, 'Max', 84000, 1, 1, '2005-02-10');
62INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (7, 'Will', 70000, 1, 1, '1982-02-10');
63INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (8, 'Raj', 65000, null, 1, '1978-02-10');
64INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (9, 'Suresh', 62000, null, 1, '1978-02-10');
65INSERT INTO employee (id, name, salary, department_id, manager, dob) VALUES (10, 'Sam', 61000, 2, 1, '1985-02-10');
66
67INSERT INTO project (id, name) VALUES (1, 'Project 1');
68INSERT INTO project (id, name) VALUES (2, 'Project 2');
69INSERT INTO project (id, name) VALUES (3, 'Project 3');
70INSERT INTO project (id, name) VALUES (4, 'Project 4');
71
72INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (1, 1, 1);
73INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (2, 1, 2);
74INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (3, 3, 3);
75INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (4, 4, 3);
76INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (5, 5, 2);
77INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (6, 6, 1);
78INSERT INTO employee_project_mapping (id, emp_id, project_id) VALUES (7, 7, 2);
1--SQL Query PostgreSQL
2
3--first max salary
4select distinct salary
5from employee
6order by salary desc
7limit 1;
8
9-- https://leetcode.com/problems/second-highest-salary/
10-- second max salary
11select distinct salary
12from employee
13order by salary desc
14limit 1 offset 1;
15
16-- second max salary
17select max(salary)
18from employee
19where salary < (select max(salary) from employee);
20
21-- if 2nd salary doesnt exist show null
22select NULLIF(
23 (select distinct salary
24 from employee
25 order by salary Desc
26 limit 1 offset 1), null
27 ) as SecondHighestSalary;
28
29-- https://leetcode.com/problems/department-top-three-salaries/
30-- top 3 salaries in each department
31select d.name, e.id, e.name, e.salary
32from employee e,
33 department d
34where e.department_id = d.id
35 and (
36 select count(distinct (e2.salary))
37 from employee e2
38 where e2.salary > e.salary
39 and e2.department_id = e.department_id
40 ) < 3
41order by (d.name, e.name);
42
43--max salary in each department
44select d.name, max(e.salary)
45from employee e,
46 department d
47where e.department_id = d.id
48group by d.id;
49
50--max salary in each department with employee name
51select d.name, e.id, e.name, e.salary
52from employee e,
53 department d
54where e.department_id = d.id
55 and (
56 select count(distinct (e2.salary))
57 from employee e2
58 where e2.salary > e.salary
59 and e.department_id = e2.department_id
60 ) < 1
61order by (d.name, e.name);
62
63--find all employee and department they work in, only show employees who have a department assigned.
64SELECT e.name, d.name
65FROM employee e
66 INNER JOIN department d ON e.department_id = d.id;
67
68--inner join
69SELECT e.name, d.name
70FROM employee e,
71 department d
72where e.department_id = d.id;
73
74--find all employee who dont have a department
75SELECT e.name, d.name
76FROM employee e
77 LEFT JOIN department d ON e.department_id = d.id
78where d.name is null;
79
80--find max salary in department even if no employee in it.
81SELECT d.name, max(e.salary)
82FROM employee e
83 RIGHT JOIN department d ON e.department_id = d.id
84GROUP BY d.name;
85
86--find department without an employee
87SELECT d.name, e.name
88FROM employee e
89 RIGHT JOIN department d ON e.department_id = d.id
90where e.name is null;
91
92--show all employee and department even if they dont have assignment
93SELECT e.name, d.name
94FROM employee e
95 FULL JOIN department d ON e.department_id = d.id;
96
97--find all employees having salary greater than average
98SELECT e.name, e.salary
99FROM employee e
100WHERE salary > (SELECT AVG(salary) from employee);
101
102-- find people with same name in same department
103SELECT e.name as emp_name, d.name as department
104FROM employee e,
105 department d
106where e.department_id = d.id
107group by emp_name, department
108having count(*) > 1;
109
110-- find all employees and their manager
111SELECT e.name, m.name
112FROM employee e,
113 employee m
114WHERE e.manager = m.id;
115
116-- find all employees who dont have a manager
117SELECT e.name, m.name
118FROM employee e
119 LEFT JOIN employee m on e.manager = m.id
120WHERE m.name is null;
121
122-- find all employees and their manager, if they dont have manager show null
123SELECT e.name, m.name
124FROM employee e
125 LEFT JOIN employee m on e.manager = m.id;
126
127-- find all employees and the projects they are working in along with department.
128-- one employee can work on multiple projects
129select e.name, d.name department, p.name project
130from employee e,
131 department d,
132 employee_project_mapping m,
133 project p
134where e.department_id = d.id
135 and e.id = m.emp_id
136 and m.project_id = p.id;
137
138-- find employees who age is greater than 25
139select e.name, e.dob, age(CURRENT_DATE, e.dob)
140from employee e
141where EXTRACT(YEAR FROM age(CURRENT_DATE, e.dob)) > 25;
142
143-- find the oldest employee
144select e.id, e.name, max(age(CURRENT_DATE, e.dob)) emp_age
145from employee e group by e.id, e.name
146order by emp_age desc limit 1;
147
148--find the project and number of employees working on it.
149select p.name project, count(*)
150from project p,
151 employee_project_mapping m,
152 employee e
153where p.id = m.project_id
154 and m.emp_id = e.id
155group by project;
156
157--find the projects with no employees
158select p.id, p.name
159from project p
160 left join employee_project_mapping m on p.id = m.project_id
161where m.emp_id is null;
162
163--find the employees with no project
164select e.id, e.name
165from employee e
166 left join employee_project_mapping m on e.id = m.emp_id
167where m.project_id is null;
168
169--oldest person in each department
170select d.name, e.id, e.name, e.dob
171from employee e,
172 department d
173where e.department_id = d.id
174 and (
175 select count(distinct(e2.dob))
176 from employee e2
177 where e.dob > e2.dob
178 and e.department_id = e2.department_id
179 ) < 1
180order by (d.name, e.name);
181
182--current date
183SELECT CURRENT_DATE;
184SELECT extract(year from CURRENT_DATE) as "Year";
185
186--find all employee born between 1980-1990
187select *
188from employee e
189where e.dob between '01-01-1980' and '01-01-1990';
190
191--find all employees who name begins with M
192select *
193from employee
194where name like 'M%';
195
196--find all employees other than Max
197select *
198from employee
199where name <> 'Max';
200
201--find all employees with name of Max
202select *
203from employee
204where name = 'Max';
205
206--find employees who are in project1 and project2
207select e.id, e.name
208from employee e,
209 employee_project_mapping m,
210 project p
211where m.emp_id = e.id
212 and m.project_id = p.id
213 and p.name = 'Project 1'
214INTERSECT
215select e.id, e.name
216from employee e,
217 employee_project_mapping m,
218 project p
219where m.emp_id = e.id
220 and m.project_id = p.id
221 and p.name = 'Project 2';
Youtube Channels
Tushar Roy - Coding Made Simple
References
https://www.youtube.com/c/NeetCode
https://designgurus.org/course/grokking-the-coding-interview
https://algs4.cs.princeton.edu/cheatsheet/
https://www.bigocheatsheet.com/
https://seanprashad.com/leetcode-patterns/