Spring Boot - Apache Kafka
Overview
Spring Boot 3 integration with Apache Kafka & Kafka streams
Github: https://github.com/gitorko/project80
Kafka
Kafka is a distributed & fault-tolerant, high throughput, scalable stream processing & messaging system.
- Kafka as publisher-subscriber messaging system.
- Kafka as queue (point-point) messaging system.
- Kafka as stream processing system that reacts to event in realtime.
- Kafka as a store for data.
Terms
- Broker: Kafka server.
- Cluster: A group of kafka brokers.
- Topic: Logical grouping of messages.
- Partition: A topic can contain many partitions. Messages are stored in a partition.
- Offset: Used to keep track of message.
- Consumer Group: Reads the messages from a topic.
- Consumer: A consumer group can have N consumers, each will read a partition. Consumers cant be more than number of partitions.
- Zookeeper: Used to track the offset, consumers, topics etc.

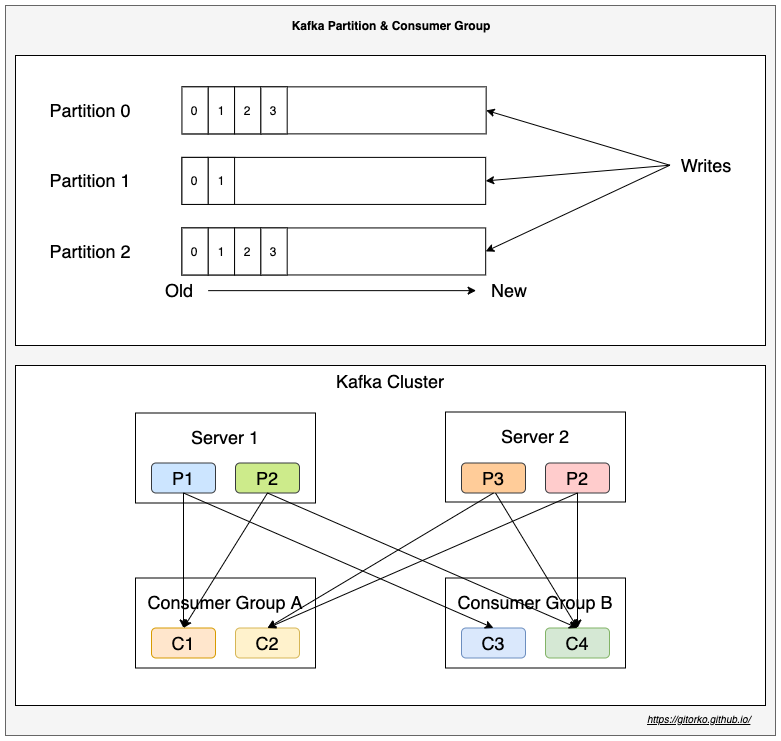
- Order is guaranteed only withing a partition and not across partitions.
- Within a consumer group a partition can be read only by one consumer.
- Leader replicates partition to other replica servers based on replication count. If leader fails then follower will become leader.
- Zookeeper manages all brokers, keeps track of offset, consumer group, topic, partitions etc.
- Once a message acknowledgement fails kafka will retry and even after certain retries if it fails, the message will be moved to dead letter.
Kafka provides high throughput because of the following
- Kafka scales because it works on append only mode, sequential disk write is faster than random access file write
- Kafka copies data from disk to network by ready with zero copy. OS buffer directly copies to NIC buffer.
There is no set limit to the number of topics that can exist in a Kafka cluster, each partition has a limit of 4000 partitions per broker, maximum 200,000 partitions per Kafka cluster
Kafka Use-Cases
- Activity tracking for high traffic website
- Processing streaming big data
- Monitoring financial data in real time
- IoT sensor data processing
Kafka stores streams of records (messages) in topics. Topics are partitioned and replicated across multiple nodes thus kafka can scale and be a distributed system. Producers publish data to the topics. Consumer groups can subscribe to topics.
Advantages
- Data Store - Kafka is append only commit log. Which means it can also act as a data store.
- Queue (point-point) - If only one consumer group subscribes to a topic it behaves like a Queue (point-point) messaging system.
- Pub-Sub - If more than one consumer group subscribe to a topic it behaves like Pub-Sub messaging system.
- Consumer Group - Number of consumers in a group must be less than or equal to number of partitions. Cant have more consumers in a group than there are partitions.
- Partition - Producer can only write to topic but which partition the data gets written to is not in its control.
- Partition - When you add a new kafka broker the partition is replicated so loss of one node doesn't crash the system.
- Ordering - Ordering of messages is guaranteed only in a partition and not across partitions.
- Offset - Consumer can choose to read records from latest or from beginning.
- Long polling - Uses poll model compared to RabbitMQ which uses push model
- Adapters - Provides adapters that can be used to write data to db and other endpoints
- Stream - Provides stream processing capabilities
Similar to spring rest template or jdbc template which abstracts the rest/jdbc calls spring provides kafka template which provides high level abstraction to interact with kafka. There is an even higher level of abstraction provided by spring cloud stream which lets we integrate with kafka or rabbitmq and other messaging systems. So when the messaging systems changes you dont need to make code changes in producer or consumer.


Code
1package com.demo.project80;
2
3import java.util.Arrays;
4import java.util.List;
5import java.util.Random;
6import java.util.UUID;
7import java.util.concurrent.TimeUnit;
8
9import com.demo.project80.domain.User;
10import lombok.extern.slf4j.Slf4j;
11import org.springframework.beans.factory.annotation.Value;
12import org.springframework.boot.CommandLineRunner;
13import org.springframework.boot.SpringApplication;
14import org.springframework.boot.autoconfigure.SpringBootApplication;
15import org.springframework.context.annotation.Bean;
16import org.springframework.kafka.core.KafkaTemplate;
17
18@SpringBootApplication
19@Slf4j
20public class KafkaProducer {
21
22 @Value(value = "${topic.name}")
23 private String topicName;
24
25 public static void main(String[] args) {
26 SpringApplication.run(KafkaProducer.class, args);
27 }
28
29 @Bean
30 public CommandLineRunner onStart(KafkaTemplate<String, User> kafkaTemplate) {
31 return (args) -> {
32 List<String> users = Arrays.asList("david", "john", "raj", "peter");
33 Random random = new Random();
34 for (int i = 0; i < 10; i++) {
35 User user = new User(users.get(random.nextInt(users.size())), random.nextInt(100));
36 log.info("Sending User: {}", user);
37 String key = UUID.randomUUID().toString();
38 kafkaTemplate.send(topicName, key, user);
39 TimeUnit.SECONDS.sleep(10);
40 }
41 };
42 }
43
44}
1package com.demo.project80;
2
3import com.demo.project80.domain.User;
4import lombok.extern.slf4j.Slf4j;
5import org.springframework.boot.SpringApplication;
6import org.springframework.boot.autoconfigure.SpringBootApplication;
7import org.springframework.kafka.annotation.KafkaListener;
8
9@SpringBootApplication
10@Slf4j
11public class KafkaConsumer {
12
13 public static void main(String[] args) {
14 SpringApplication.run(KafkaConsumer.class, args);
15 }
16
17 @KafkaListener(id = "my-client-app", topics = "${topic.name}", groupId = "group-01")
18 public void topicConsumer(User user) {
19 log.info("Received User : {}", user);
20 }
21
22}
1version: '2'
2services:
3 zookeeper:
4 container_name: zookeeper
5 image: 'bitnami/zookeeper:latest'
6 ports:
7 - 2181:2181
8 environment:
9 - ALLOW_ANONYMOUS_LOGIN=yes
10 kafkaserver:
11 hostname: kafkaserver
12 container_name: kafkaserver
13 image: 'bitnami/kafka:latest'
14 ports:
15 - 9092:9092
16 depends_on:
17 - zookeeper
18 environment:
19 - KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
20 - KAFKA_ADVERTISED_HOST_NAME=kafkaserver
21 - ALLOW_PLAINTEXT_LISTENER=yes
22 links:
23 - zookeeper:zookeeper
24 kafka-ui:
25 container_name: kafka-ui
26 image: provectuslabs/kafka-ui:latest
27 ports:
28 - 9090:8080
29 depends_on:
30 - zookeeper
31 - kafkaserver
32 environment:
33 KAFKA_CLUSTERS_0_NAME: local
34 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafkaserver:9092
35 KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
The group id of your client which uses group management to assign topic partitions to consumers The auto-offset-reset=earliest ensures the new consumer group will get the oldest available message.
We can have multiple kafka listener for a topic with different group id A consumer can listen to more than one topic. We have created the topic 'mytopic' with only one partition. For a topic with multiple partitions, @KafkaListener can explicitly subscribe to a particular partition of a topic with an initial offset.
1@KafkaListener(topics = "topic1", group = "group1")
2@KafkaListener(topics = "topic1,topic2", group = "group1")
3@KafkaListener(topicPartitions = @TopicPartition(topic = "topic1",
4 partitionOffsets = {
5 @PartitionOffset(partition = "0", initialOffset = "0"),
6 @PartitionOffset(partition = "2", initialOffset = "0")
7}))
Kafka Streams
Kafka Streams has stream-table duality. Tables are a set of evolving facts. Each new event overwrites the old one, whereas streams are a collection of immutable facts. Kafka Streams provides two abstractions for Streams and Tables. KStream handles the stream of records. KTable manages the changelog stream with the latest state of a given key For not partitioned tables we can use GlobalKTables to broadcast information to all tasks.
When we use other projects like apache spark, storm, flink we write code and copy the jar to the nodes where the actual work happens. With the introduction of kafka stream we can now write our processing logic for streams, then it can run anywhere the jar can run. KafkaStreams enables us to consume from Kafka topics, analyze or transform data, and potentially, send it to another Kafka topic.
We will now count the users by age group.
Code
1package com.demo.project80;
2
3import java.util.concurrent.TimeUnit;
4
5import com.demo.project80.domain.User;
6import lombok.extern.slf4j.Slf4j;
7import org.apache.kafka.common.serialization.Serde;
8import org.apache.kafka.common.serialization.Serdes;
9import org.apache.kafka.streams.KafkaStreams;
10import org.apache.kafka.streams.KeyValue;
11import org.apache.kafka.streams.StreamsBuilder;
12import org.apache.kafka.streams.Topology;
13import org.apache.kafka.streams.kstream.Consumed;
14import org.apache.kafka.streams.kstream.Grouped;
15import org.apache.kafka.streams.kstream.KStream;
16import org.apache.kafka.streams.kstream.KTable;
17import org.springframework.beans.factory.annotation.Value;
18import org.springframework.boot.CommandLineRunner;
19import org.springframework.boot.SpringApplication;
20import org.springframework.boot.autoconfigure.SpringBootApplication;
21import org.springframework.context.annotation.Bean;
22import org.springframework.kafka.config.KafkaStreamsConfiguration;
23import org.springframework.kafka.support.serializer.JsonSerde;
24
25@SpringBootApplication
26@Slf4j
27public class KafkaStream {
28
29 private static final Serde<String> STRING_SERDE = Serdes.String();
30
31 @Value(value = "${topic.name}")
32 private String topicName;
33
34 public static void main(String[] args) {
35 SpringApplication.run(KafkaStream.class, args);
36 }
37
38 @Bean
39 public CommandLineRunner streamData(KafkaStreamsConfiguration kStreamsConfig) {
40 return (args) -> {
41 StreamsBuilder streamsBuilder = new StreamsBuilder();
42 KStream<String, User> streamOfUsers = streamsBuilder
43 .stream(topicName, Consumed.with(STRING_SERDE, new JsonSerde<>(User.class)));
44
45 streamOfUsers.foreach((k, v) -> {
46 log.info("user: {}, age: {}", v.getName(), v.getAge());
47 });
48
49 KTable<String, Long> employeeCountByCompany = streamOfUsers
50 .map((k, v) -> new KeyValue<>(v.getAge(), String.valueOf(v.getAge())))
51 .groupBy((k, w) -> w, Grouped.with(STRING_SERDE, STRING_SERDE))
52 .count();
53 employeeCountByCompany.toStream().foreach((w, c) -> log.info("Age: {} , Count: {}", w, c));
54
55 Topology topology = streamsBuilder.build();
56 KafkaStreams streams = new KafkaStreams(topology, kStreamsConfig.asProperties());
57 streams.cleanUp();
58 streams.start();
59 TimeUnit.SECONDS.sleep(10);
60 Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
61 };
62 }
63
64}
Run the main method of KafkaStream.
Setup
1# Project 80
2
3Spring Boot & Kafka
4
5[https://gitorko.github.io/spring-apache-kafka/](https://gitorko.github.io/spring-apache-kafka/)
6
7### Version
8
9Check version
10
11```bash
12$java --version
13openjdk version "21.0.3" 2024-04-16 LTS
14```
15
16### Kafka
17
18To run kafka we need zookeeper, use the docker compose command to run kafka as a container
19
20For windows ensure the C:\Windows\System32\drivers\etc\hosts file has these 2 entries.
21For link ensure /etc/hosts has these 2 entries.
22
23```bash
24127.0.0.1 zookeeper
25127.0.0.1 kafkaserver
26```
27
28```bash
29docker-compose -f docker/docker-compose.yml up
30```
31
32To create topic
33
34```bash
35docker exec -it kafkaserver /bin/bash
36/opt/bitnami/kafka/bin/kafka-topics.sh --create --replication-factor 1 --partitions 1 --topic mytopic.000 --bootstrap-server localhost:9092
37```
38
39Describe topic
40
41```bash
42docker exec -it kafkaserver /bin/bash
43/opt/bitnami/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
44/opt/bitnami/kafka/bin/kafka-topics.sh --describe mytopic.000 --bootstrap-server localhost:9092
45```
46
47To delete topic
48
49```bash
50docker exec -it kafkaserver /bin/bash
51/opt/bitnami/kafka/bin/kafka-topics.sh --delete --topic mytopic.000 --bootstrap-server localhost:9092
52```
53
54Clean up
55
56```bash
57docker-compose -f docker/docker-compose.yml stop
58docker rm kafka-ui kafkaserver zookeeper
59```
60
61Restart
62
63```bash
64docker-compose -f docker/docker-compose.yml start
65```
66
67Dashboard for kafka, wait for a few seconds as it takes time to come up.
68
69Open [http://localhost:9090/](http://localhost:9090/)
70
71### Dev
72
73To run the code.
74
75```bash
76./gradlew clean build
77
78./gradlew :kserver:build
79./gradlew :kclient:build
80./gradlew :kcommon:build
81./gradlew :kstream:build
82
83./gradlew :kserver:bootRun
84./gradlew :kclient:bootRun
85./gradlew :kstream:bootRun
86```References
https://www.baeldung.com/java-kafka-streams
https://kafka.apache.org/quickstart
https://baeldung-cn.com/java-kafka-streams-vs-kafka-consumer